Final
Summary
I implemented three max flow algorithms - Edmonds-Karp, Dinic's, and Push-relabel - both sequentially and in parallel using OpenMP, and analyzed speedups obtained. In particular, I focused on a lock-free Push-relabel algorithm, and was able to obtain up to 6x speedup on tested graphs. I also parallelized this algorithm on GPUs with a single CUDA thread per vertex to benchmark performance, and noticed poor performance, for reasons discussed later. Finally, I wrote a small class-based library to easily represent graphs and run max flow algorithms on them. Tests were run on GHC35, which has an 8-core hyperthreaded CPU and a GTX 1080 GPU. All tests were run using fixed, randomly generated connected graphs with max edge capacity of 50, and results were averaged over multiple trials. Code can be found on my GitHub.
Example usage of the library:
FlowGraph graph(6); std::vector<std::tuple<int, int, int>> edges; edges.push_back(std::make_tuple(0, 1, 4)); // (from, to, capacity) edges.push_back(std::make_tuple(0, 2, 2)); edges.push_back(std::make_tuple(1, 3, 3)); edges.push_back(std::make_tuple(2, 4, 3)); edges.push_back(std::make_tuple(3, 5, 2)); edges.push_back(std::make_tuple(4, 5, 4)); edges.push_back(std::make_tuple(3, 0, 5)); graph.AddEdges(&edges); graph.DeleteEdge(3, 0); auto result = graph.FlowEdmondsKarp();
Background
See main section "Background" for motivation. All of these algorithms operate on a graph with specified edge capacities, and output the value of the max flow along with all edges that have positive flow pushed on them. The main challenge is that most flow algorithms are not inherently parallelizable. Many algorithms use the concept of a residual graph, which is essentially the state of the graph after flow is pushed during a single iteration. Therefore, synchronization is needed between iterations - flow cannot be pushed on the residual graph if the residual graph is not yet created. Algorithms that don’t use residual graphs, such as Push-relabel, instead require massive amounts of system-wide synchronization, as explained later. As well, for general graphs, there is not much data locality. This is especially true for the Push-relabel algorithm, which keeps track of heights and excess flow values for each node, which needs to be constantly accessed by all neighbors. For all of these reasons, there is not much research done in parallel flows. As well, existing sequential algorithms are, in most practical uses, extremely fast.
The three algorithms I investigated were the following:
Edmonds-Karp
𝑂(𝑛𝑚²). Uses BFS as a subroutine to pick the shortest path in the residual graph at each iteration. Not parallelizable between iterations.Dinic's
𝑂(𝑛²𝑚). Uses BFS at each iteration to construct a layered graph (edges only from depth 𝑑 to 𝑑+1 from the source vertex). Then, the algorithm uses DFS to find a blocking flow, where every path in the layered graph has a saturated edge (no residual capacity). Only the layered graph construction is parallelizable.Push-relabel
𝑂(𝑛²𝑚). Uses the idea of height labels and excess flow – if a node has excess flow, try to push it to a lower height neighbor, or else try to increase your height. This algorithm is much more parallelizable (can parallelize over vertices), and as a result was the main focus of this project. Due to excess flows, this algorithm does not necessarily maintain a valid flow until the very end. An analogy to how this algorithm operates is how water flows through pipes.Approach
All code was done in C++/CUDA. CPU parallelism was done with OpenMP. For both Edmonds-Karp and Dinic's, the only really parallelizable part of the algorithms are the BFS subroutines. Therefore, I used modified versions of my OpenMP parallel top-down BFS implementation from assignment 3 in these algorithms to obtain speedups. Just as in the assignment, threads map to local frontiers that are then merged together with fetch-and-add operations. The main focus of parallelizing these two algorithms was for analysis (see the "Results" subsection), and not so much a focus on the code itself. I was originally intending on trying to parallelize these algorithms on GPUs as well, but realized that it wouldn't be effective since the only parallelizable routine is BFS, which due to access patterns in general graphs and low arithmetic intensity, would not benefit (and would most likely observe negative speedups) from GPU parallelization.
My main focus was on parallelizing the Push-relabel algorithm. This algorithm can be parallelized across vertices. However, all vertices need to see global residual capacity and excess flow updates, as well as height relabelings. Each vertex also needs to know when to terminate – local termination (excess flow is 0) is not good enough, since a node could gain more excess flow later on. Therefore, most attempts to parallelize Push-relabel require a lot of global barriers and locks, which severely limits parallelism.
After investigation, I came across research on a lock-free parallel Push-relabel algorithm. In particular, I based my implementation on a research paper by Bo Hong, cited below. The key insight is that instead of pushing flow to any neighbor with lower height, you only push flow to your lowest height neighbor. With this small modification (and a few others), Hong proved correctness of asynchronous push and relabel operations. Therefore, in an idealized setting, you can have one thread per vertex, that repeatedly tries to perform push and relabel operations as long as the node has excess flow. In order to avoid locks, however, since many global values still need to be updated, quite a few fetch-and-add operations are necessary. In order to determine global termination without barriers, as the initial research paper suggests (which makes the algorithm not truly lock-free), a key observation that must be made is that the Push-relabel algorithm starts out by pushing all possible flow out of the source node (in the preflow stage), and the sink vertex has no incoming flow. As the algorithm proceeds, we notice that net flow out of the source is monotonically decreasing, and similarly net flow into the sink is monotonically increasing. Therefore, a sufficient termination condition is when these two values are equal. Two global values that are updated with fetch-and-add operations are maintained to represent these values, and each thread terminates only if the two values are equal.
On the CPU, threads were mapped to chunks of vertices, and were responsible for polling for non-zero excess flows for all of its vertices. On the GPU, I experimented with actually having one thread per vertex.
Results
Edmonds-Karp is more parallelizable than Dinic's
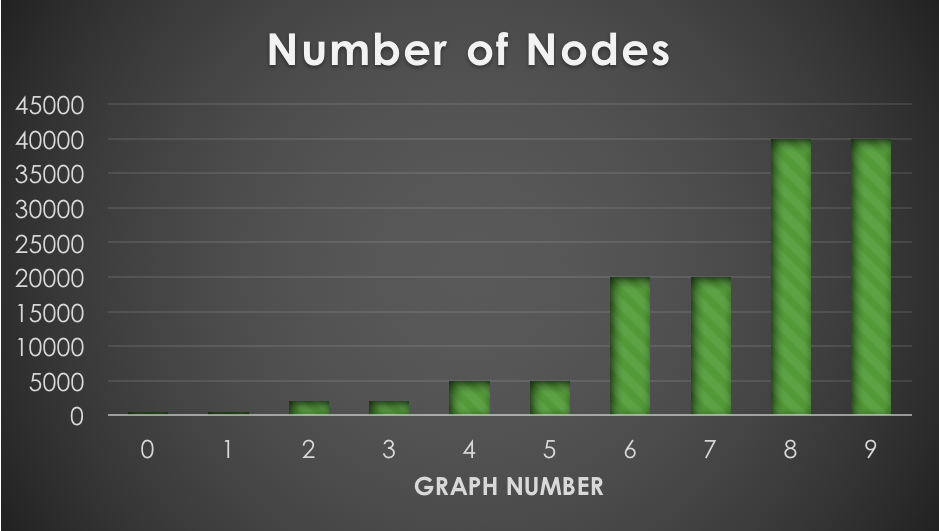
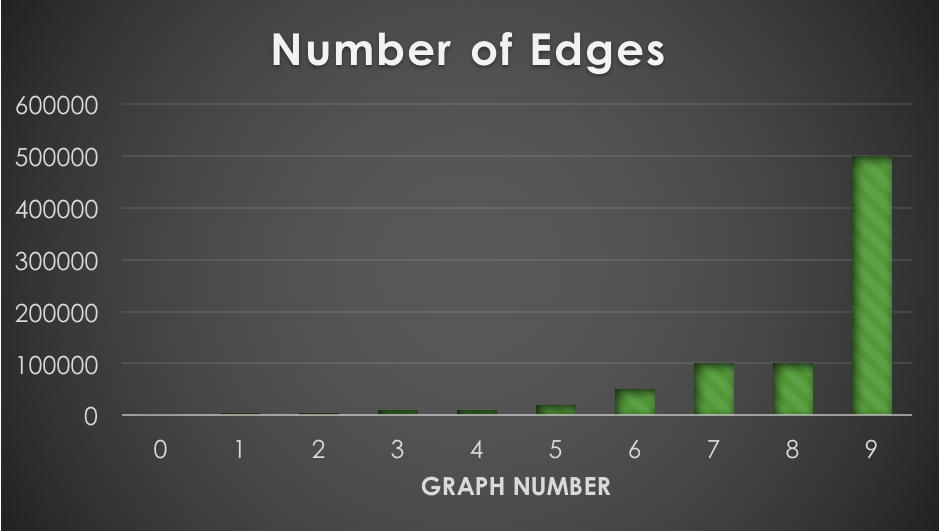
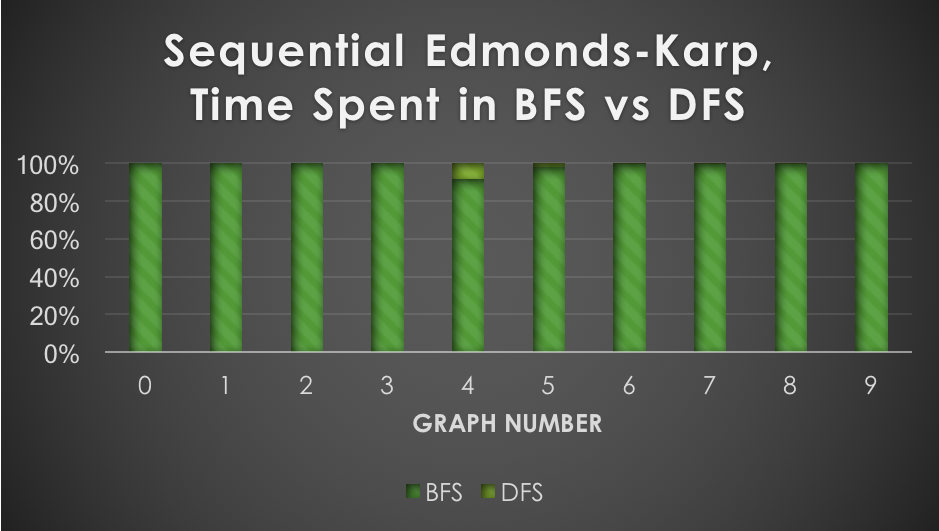
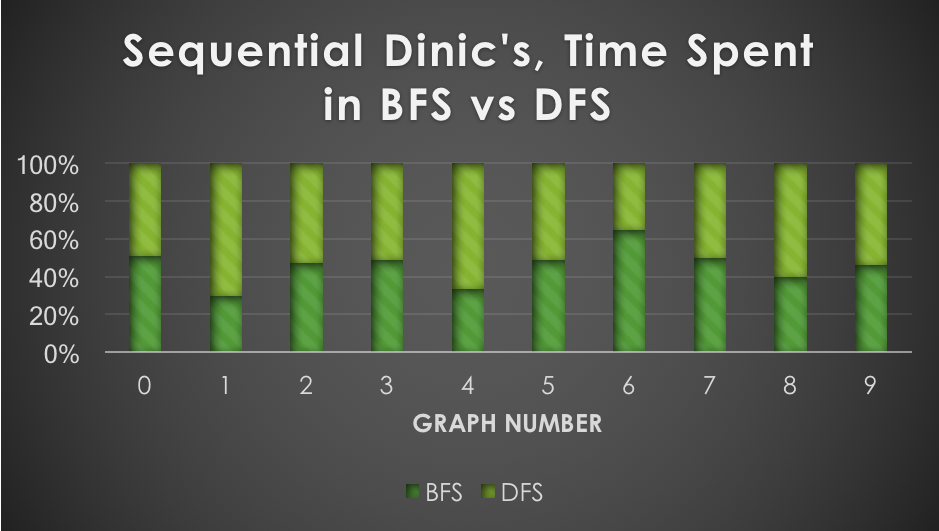
The number of nodes and edges of the ten fixed, randomly generated graphs used for testing are shown in the first row of graphs. Larger graphs weren't used due to memory constraints, and to prevent individual test runs from going longer than a few minutes. These results made it evident that parallelizing BFS would likely provide a larger speedup to Edmonds-Karp than to Dinic's, since almost all the time of Edmonds-Karp is spent in BFS. These observations correspond exactly with the observed speedups (tested against sequential baseline):
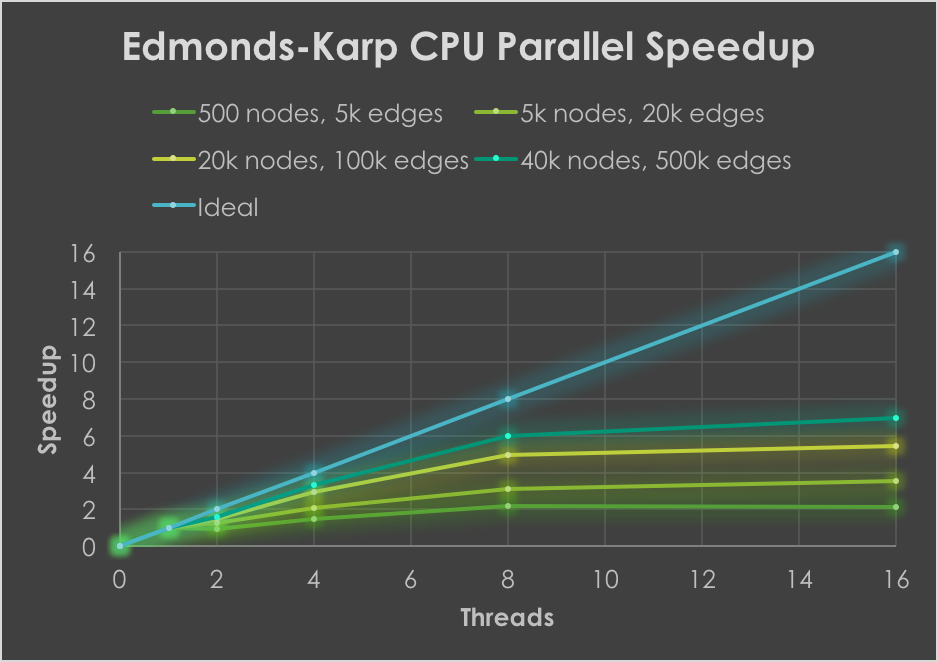
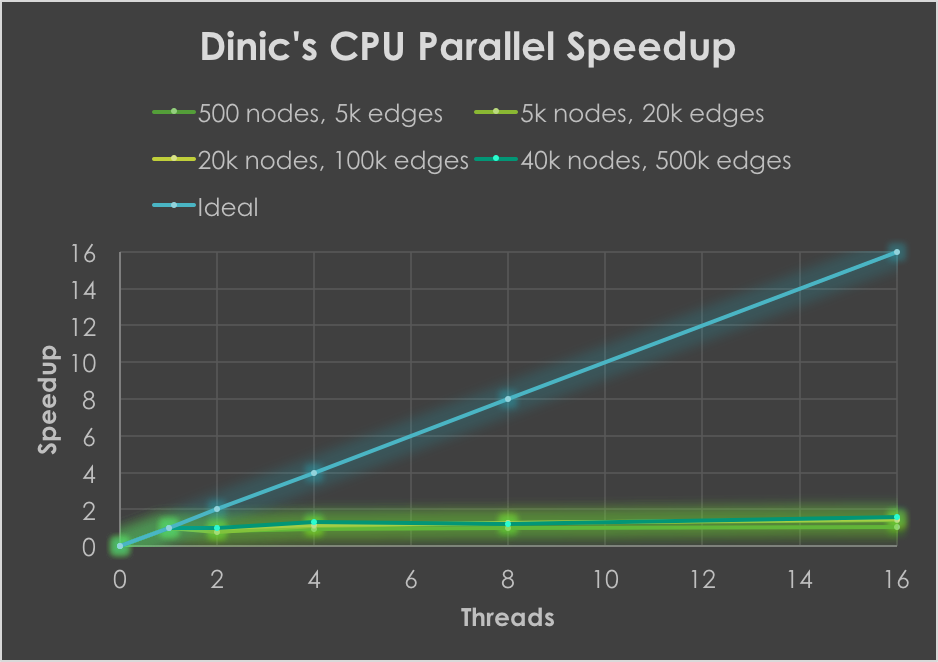
Edmonds-Karp observed speedups of over 6x, generally increasing as graph size increased. Atomic fetch-and-add operations in BFS as well as low arithmetic intensity prevent much further speedup from being obtained. Dinic's, however, did not get speedups greater than 2x across all tested graphs. This is for a few reasons (besides the lower overall amount of time spent in BFS). First, each time the BFS subroutine is used in Dinic's, the overall depth of the layered graph increases by at least 1. This depth can be at most the number of vertices at termination. However, the larger the initial depth from source to sink in the graph, the fewer number of times the layered graph has to be reconstructed. For instance, if the graph initially has an s-t depth of 𝑛-1, then only one layered graph would be created. Therefore, the speedup obtained by parallelizing the BFS subroutine is restricted by the initial s-t depth in the graph, which is not largely dependent on graph size. Besides this, sequential Dinic's is already one of the fastest flow algorithms for practical use, so squeezing out even more performance is difficult due to the added overhead associated with threads. In fact, Dinic's greatly outperformed both Edmonds-Karp and Push-relabel in all tested graphs.
Lock-free parallel Push-relabel: promising speedups
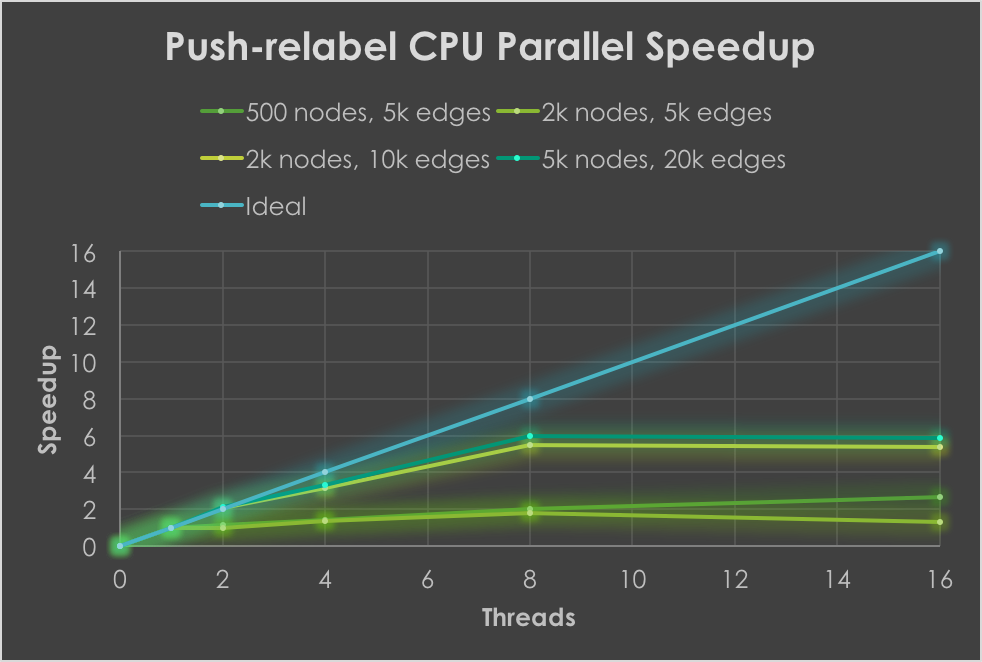
The speedups observed are promising, showing up to 6x over sequential on tested graphs. There is a decent amount of contention due to the large number of atomic fetch-and-add operations required, which therefore limits further speedup. There are some interesting issues that arise with the Push-relabel algorithm, however. First, parallelism, and even sequential performance, greatly varies depending on the number of active (excess flow > 0) nodes at a given step. This depends on not only the initial structure of the graph, but also the ordering of push and relabel operations done. As a result, speedup is not very linear in graph size (especially due to randomness), but still follows a general trend. Also note that smaller graph instances were tested here, since the algorithm generally took quite a while to run, especially on larger instances, which made data collection over multiple trials take too long. There are some optimizations that I did not have time to investigate, which use FIFO orderings, dynamic trees, etc., to improve practical performance of Push-relabel.
Lock-free parallel Push-relabel in CUDA
In the spirit of Bo Hong's paper, I decided to see what would happen if you really did have one thread per vertex, instead of having a single thread responsible for a chunk of vertices. I decided to do this in CUDA, and observed that on most graphs tested, GPU performance was at least 10x worse than sequential! There are quite a few reasons for this. First, you can’t take advantage of shared memory for general graphs, since there are no regular access patterns and in general there is quite poor locality. Second, I needed to use global memory to update height and flows since other nodes outside of the thread block needed this information. And third, and possibly worst of all, there is a ton of contention - |𝑉| threads all trying to fetch-and-add on multiple values! Realistically, CUDA would work well on image graphs for segmentation, and there is some research done in this field. Shared memory can be used, and thread blocks can do wave flow pushes, with each thread first pushing flow column-wise and then row-wise within a block. Communication is limited as well, since only flow that is pushed across the border of the block needs to be communicated.
References
1. 15-451 notes.
2. Wikipedia articles on Edmonds-Karp, Dinic's, and Push-relabel for sequential algorithm descriptions/information.
3. Geeksforgeeks.org for sequential algorithm descriptions/information.
4. This website for Dinic's sequential reference (in particular, the idea of passing forward the minimum flow as an argument in the DFS routine instead of backtracking to compute it).
5. A Lock-free Multi-threaded Algorithm for the Maximum Flow Problem, Bo Hong.
